
实测 Manus:首个真干活 AI,中国造(附50个用例 + 拆解)
实测 Manus:首个真干活 AI,中国造(附50个用例 + 拆解)Manus 的产品名,意思为“手”,来自拉丁文 "mens et manus" —— 知行合一。它体现了一种理念:知识和智慧必须通过身体力行才能对世界产生正向影响。这就是 Manus 的追求,为 LLM 做一双能巧妙调用工具的手,从而扩展人的能力,让你心中的愿景成为现实。
来自主题: AI资讯
13691 点击 2025-03-06 11:47
 搜索
搜索
Manus 的产品名,意思为“手”,来自拉丁文 "mens et manus" —— 知行合一。它体现了一种理念:知识和智慧必须通过身体力行才能对世界产生正向影响。这就是 Manus 的追求,为 LLM 做一双能巧妙调用工具的手,从而扩展人的能力,让你心中的愿景成为现实。
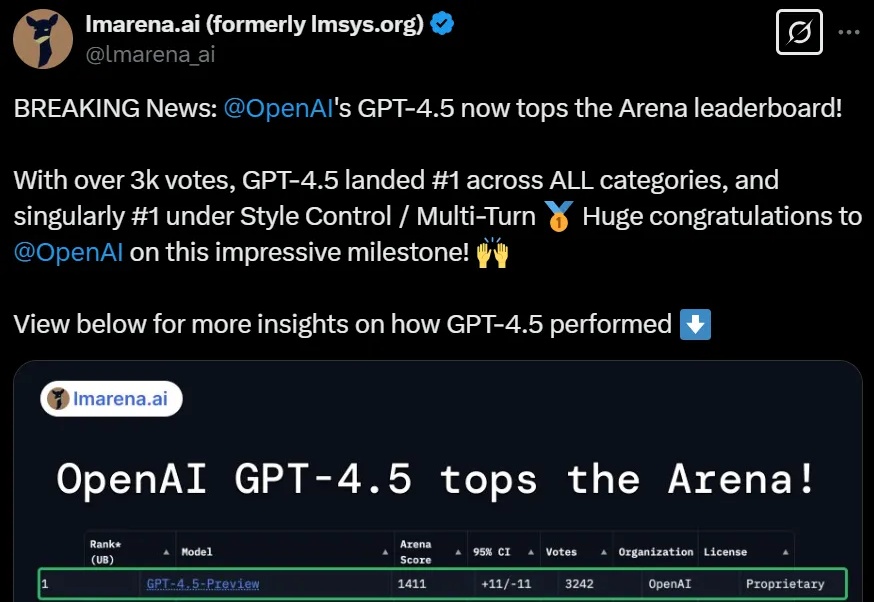
在知名AI排行榜LM Arena中,曾全班垫底的GPT-4.5竟一度拿下第一?甚至在数学、编程等领域表现优异,这反常的表现让网友们一度质疑:大模型竞技场莫非被LLM操纵了?不过网友们在实测后却惊讶发现,GPT-4.5的确情商爆表,不用推理就能理解人类的深层意图!
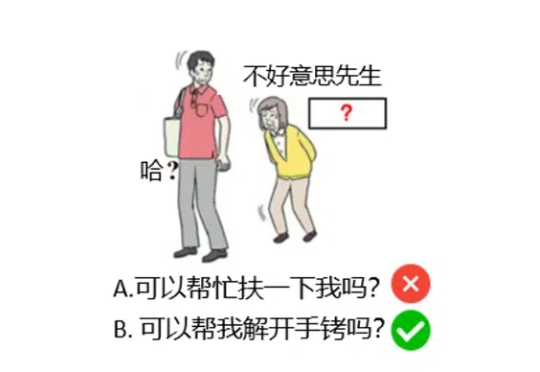
在大语言模型 (LLM) 的研究中,与以 Chain-of-Thought 为代表的逻辑思维能力相比,LLM 中同等重要的 Leap-of-Thought 能力,也称为创造力,目前的讨论和分析仍然较少。这可能会严重阻碍 LLM 在创造力上的发展。造成这种困局的一个主要原因是,面对「创造力」,我们很难构建一个合适且自动化的评估流程。

本文深入解析一项开创性研究——"Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning",该研究通过基于规则的强化学习技术显著提升了语言模型的推理能力。微软亚洲的研究团队受DeepSeek-R1成功经验的启发,利用结构化的逻辑谜题作为训练场,为模型创建了一个可以系统学习和改进推理技能的环境。

我们现在使用 LLM 来处理所有的理解工作,并确保我们不会向用户发送任何生成文本,这样我们就可以完全自信地说,我们没有幻觉的风险,没有提示注入和劫持等风险。
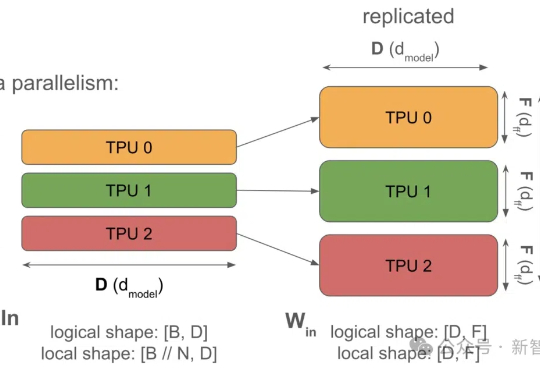
谷歌团队发布LLM硬核技术教科书,从「系统视图」揭秘LLM Scaling的神秘面纱。Jeff Dean强调书中藏着谷歌最强AI模型Gemini训练的更多信息。
最初,查询扩展是为那些靠关键词匹配来判断相关性的搜索系统设计的,比如 tf-idf 或其他稀疏向量方案。这类方法有些天然的缺陷:词语稍微变个形式,像 "ran" 和 "running",或者 "optimise" 和 "optimize",都会影响匹配结果。虽然可以用语言预处理来解决一部分问题,但远远不够。技术术语、同义词和相关词就更难处理了。

在当今的 AI 领域,图灵奖得主 Yann LeCun 算是一个另类。即便眼见着自回归 LLM 的能力越来越强大,能解决的任务也越来越多,他也依然坚持自己的看法:自回归 LLM 没有光明的未来。
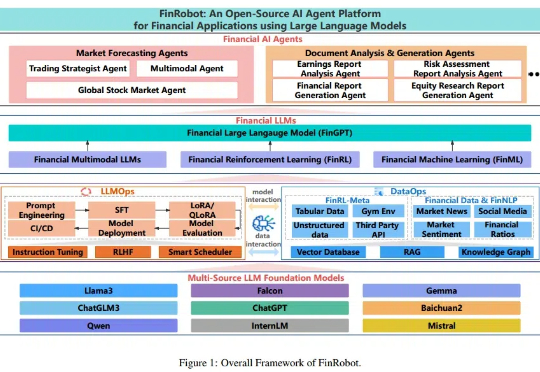
随着金融机构和专业人士越来越多地将大语言模型(LLMs)纳入其工作流程中,金融领域与人工智能社区之间依然存在显著障碍,包括专有数据和专业知识的壁垒。本文提出了 FinRobot,一种支持多个金融专业化人工智能智能体的新型开源 AI 智能体平台,每个代理均由 LLM 提供动力。
「慢思考」(Slow-Thinking),也被称为测试时扩展(Test-Time Scaling),成为提升 LLM 推理能力的新方向。近年来,OpenAI 的 o1 [4]、DeepSeek 的 R1 [5] 以及 Qwen 的 QwQ [6] 等顶尖推理大模型的发布,进一步印证了推理过程的扩展是优化 LLM 逻辑能力的有效路径。